
Autorenfreundlich Bücher kaufen?!
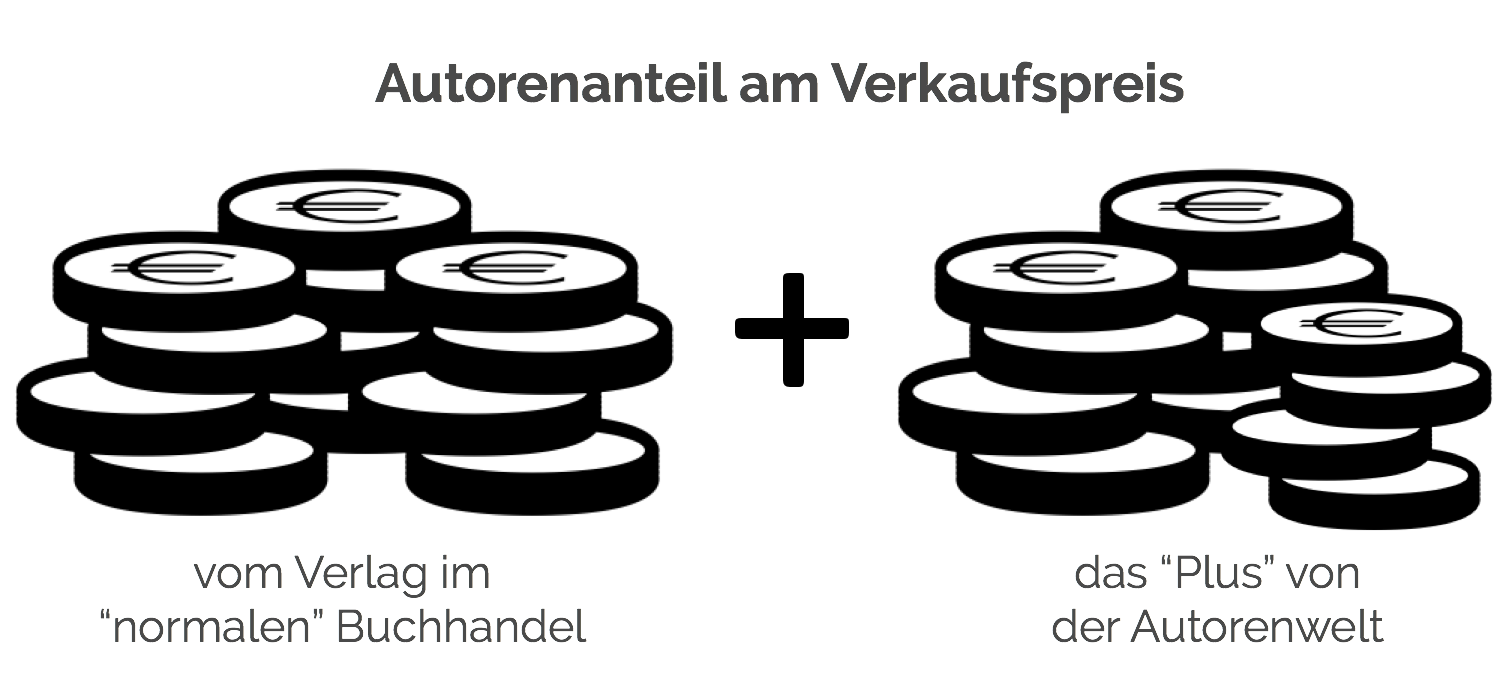
Beschreibung
O rápido desenvolvimento da Internet e das técnicas de publicação na Web criam numerosas fontes de informação publicadas como páginas HTML na World Wide Web. Contudo, há muita informação redundante e irrelevante também em páginas web. Os painéis de navegação, tabelas de conteúdo (TOC), anúncios, declarações de direitos de autor, catálogos de serviços, políticas de privacidade, etc. em páginas web são considerados como conteúdo relevante e irrelevante. Tais informações tornam várias tarefas de prospecção de páginas web, tais como o rastejamento de páginas web, classificação de páginas web, classificação baseada em ligações, complexo de destilação tópica.
Details
| Verlag | Edições Nosso Conhecimento |
| Ersterscheinung | 21. August 2022 |
| Maße | 22 cm x 15 cm x 0.4 cm |
| Gewicht | 96 Gramm |
| Format | Softcover |
| ISBN-13 | 9786205093078 |
| Seiten | 52 |
Bekannt durch


